Ok the title might be rather cryptic, but today I like to blog about some of the changing details I have been working on since the last time.
As some of you might now, Nepomuk is going to change. Sebastian already blogged about the new
Data Management Service and why it is a good thing. Now Conquirere is ready for this bright future as it relies nearly completely on the new API.
What does this change now? Not much for the end-user to be honest. But it is a great change in the background that allows for some functions that were very hard to do beforehand.
- Automatic merging of duplicate entries
- Merging of user selected entries
- Automatic type checking of the inserted entries
- Identify what changes are done with Conquirere
Especially the last part is great. Currently, if you tested the program it produced a lot of entries in Nepomuk and often not all of them are removed when you remove some publications (the chapters or the websites connected to it for example). This leaves a lot of junk in the database you don't need anymore.
From now on, you can test the program without any fear. You can always simply clean the Nepomuk database from all entries created or changed by Nepomuk without altering the other parts of the Nepomuk storage. One of the greatest things that come with the new dms api.
So the dms change took some time, but wasn't the only thing I've changed. I did fix a few bugs and produced a few more while doing the transition. Also I've changed a few other parts I didn't like.
UI Changes
The most noticeable change is the refactoring of the ui. I have replace the QDockwidgets by a QSplitter layout. As it seems there is no need to freely rearrange the components of the ui this seems to be a better solution. Now the ui has a fixed layout, but you can simply hide parts of it by collapsing it to the side.
To automate this process a little bit further, I added 3 buttons to change the "mode" of the ui view.
Now there is a
"full view mode" that displays all parts of the ui at once. When you like to scroll trough your library there is the
"project view mode" which simply hides/collapse the document preview panel and when you want to work with your documents, you can switch to the
"document view mode" which hides/collapse the library/resource table and let you concentrate on the document. If you need even more space, you can hide/collapse the right side panel too and you would end up with okular (as this is used as kpart to show your files).
 |
| Document view |
 |
| Project/Library view |
 |
| Full view |
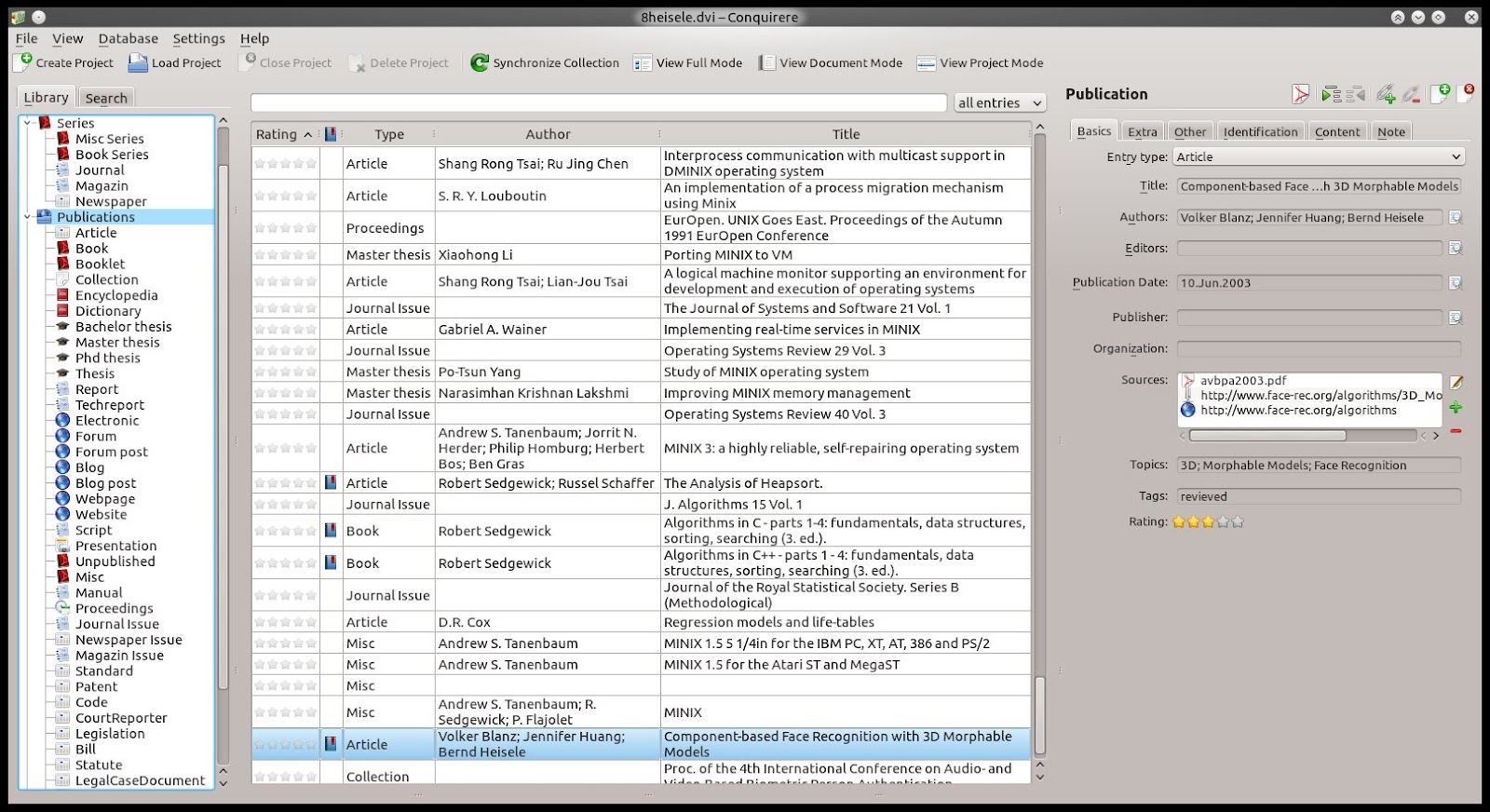
I have also simplified the way you can add your sources (files, remote files, websites).
Additionally you can now add "cited sources" so you can "quickly" check what other papers might be interesting regarding the one you are looking at. Currently you have to add this information manually. In the future I hope such information can be retrieved automatically via pdf parsing or from the web.
Also there is now no extra fields for the note content anymore, instead any kind of note is created as a pimo:Note which is a sub-resource of the publication (or document / email / event / reference / series / webpage). So from now on, bibtex files that have keys like note-1, note 2 etc are handled correctly too.
The "multiply selection" widget is another big change.
Beforehand it was a pain to to any kind of action on several files, especially deleting them. Now you can simply select several resources and do some actions with them, including merging them into 1 resource (thanks to the new dms api this was really easy to implement).
Nepomuk auto-completion is now done based on a live Nepomuk search (same way krunner does it). So at any time there is data from the database available to help you to complete your text.
 |
| Multi-selection widget |
 |
| Nepomuk auto-completion |
 |
| Manage cited sources |
The imported keywords for the publications are not handled as simple tags anymore, but will be imported as pimo:Topic. This will reduce the clutter in other parts of the system. You can still tag your publication though. But now a publication will have topics such as "face recognition, fantastic math solution, solution to world peace" and you can add tags like "important, reviewed, needs attention"
Zotero changes
The other bigger part I have changed is the Zotero integration. Now I can handle Zotero groups with more than 50 items (forgot to add this beforehand). Also child items (notes) are downloaded and added to the publication, as well as files, that can be downloaded into a specified directory. Sadly uploading files isn't working at the moment, as I have no idea how to do that via the Zotero API.
New is also the merge dialog. As soon as the item you want to sync with changed on the server, you get a neat little dialog
(unless you selected to use always the server/local version) that allows you to specify what changes you really want in your database.
 |
| Zotero merge dialog |
That's it for now.
There is still a lot to do and I still do not recommend to use Conquirere in a productive environment, but now I feel comfortable to recommend proper testing. Conquirere won't mess with your system in a way you can't simply wipe all the changes it did anymore. Also as long as you don't upload anything to Zotero, it can't mess with your Zotero data too, but even the upload should work (apart from the bugs that might still be there).
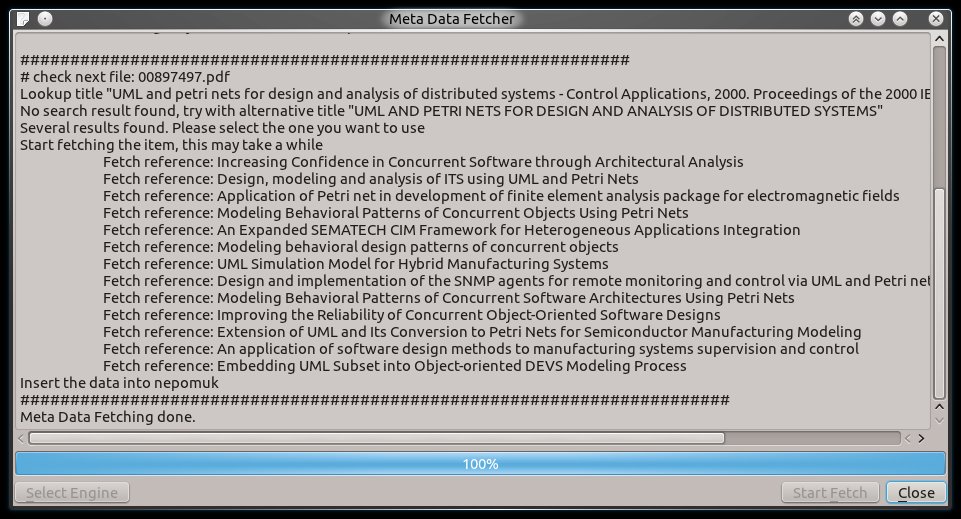
For the next step I like to add the right magic. Sebastian already showed how great automatic meta data fetching will be for the system and I think this should be expanded. Not only
tv-shows, but also any other media file and of course text document should have a service that fetches all kind of meta data in the background. This will lead to a magic system that knows more about your files than you do and allows to bring Nepomuk to its full potential.
Lets hope we can make this dream come true, as soon as possible.