Tuukka told me he developed a python plugin based Konqueror system that extracts publication relevant metadata from the currently visited website. If you know Zotero, this should remind you of the translators they are already using.
Extracting metadata from the web is a nice addition to the whole Nepomuk idea. There already exist a few implementations to extract tvshows, websites, movies and there was once a GSoC fully related to this topic.
One of the comments below Sebastians tvshow extractor was about the extension to also fetch anime data. Of course this is just one idea, there are hundreds of other sources where such data can be retrieved from. Also why stop with video files, there also exist music, publications, books and other files where additional metadata from the web can be a real help.
Now we could start to write a new program for any website we want to fetch the data from, but at the end we will only have a lot of copy and past code with some minor changes in it.
As I wanted to add such a metadata extraction for my Conquirere program anyway I sat down and thought of a more general way to combine all of this.
The "Nepomuk-Metadata-Extractor" was born. Hopefully this time the name was better chosen than the last one.
So what is this all about?
I sat down with Tuukka and combined his great python work with most of what Sebastian created for his tvshow stuff.
The end result is now a small little program, that can be called from the command line with the url of the file or folder you want to scan. Also you can simple select the right action from within dolphin if you prefer.
At the moment the program will detect if you scan publications (.pdf or .odt) or if it is a movie/tvshow.
In case you have a movie, you can fetch all the necessary data from imdb, for the tvshow it will fail, as I haven't implement this part.


The publication scan will do some more neat things.


The publication scan will do some more neat things.
First It starts by retrieving as much information from the file as possible.
This is done by scanning the RDF part of it. As most of my pdf articles have lousy RDF metadata attached to them, I also try to extract the title from the first page of the pdf.
Now that we got as much information as possible the program starts a search via Microsoft Academic Search to get the relevant abstract, bibtex data and all references used by the publication and fills the nepomuk database with it.
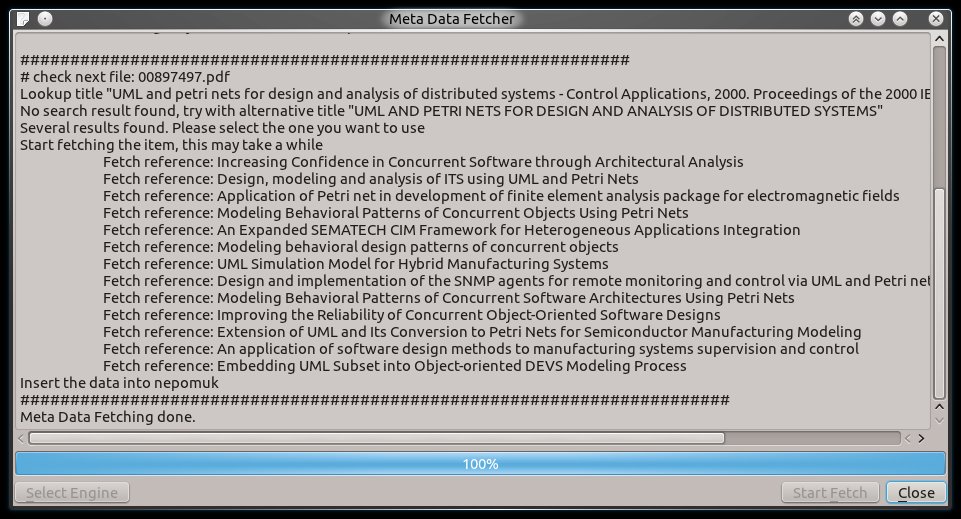

But what about the python part I've talked about earlier?
The actual search and extract job is done by a really simple to write python file. Currently I have written only two of them, but in the future you can extend it easily and then select the the right backend directly from the program.
So here we are with a new little program.
I will add this functionality into Conquirere later and hopefully Tuukka will release his Konqueror plugin later on too.
The question is just, should I add support for tvshows?
Is this the right way to start a more general web extraction service?
What do you think about this?
It could be extended with a KCM, so that someone can specify the default engine used for searching. Also a backup search engine, if the first one fails.
Sebastian also added a Nepomuk:Service so his fetcher is executed once the libstreamanalyzer adds a new video file into the storage, the same could be done here just for all kind of files.
Currently the whole system is created around files to scan, but it is also very easy to extend it, so any kind of nepomuk resource can be fed to the python parts to fetch all kind of data from the web.
If you want to try it out, the sources are currently located in my scratch repo and soon in the KDE playground.
Would be cool if subtitles of movies could be fetched as metadata. e.g. this could be used in dolphin with a service menu. "Watch movie with subtitles". The preferred language should be configurable.
ReplyDeleteFetching the subtitles might be a good addition, could be done in the same way the tvshow fetcher gets the season/episode banners.
DeleteStarting the movies with subtitles is on the other hand not in the scope of this.
I found it very hard to find a properly synchronized source of subtitles.
DeleteI really wanted to store subtitles in Nepomuk for my subtitle search program.
A side from subtitles it would be cool if Nepomuk could handle lyrics too. I often face the problem that I remember some words from a song but not the name. Then I have to search it from Google and with luck I might find the name. If this could be done straight from media player or file manager it would be totally awesome.
ReplyDeleteOne of the big possibilities with subtitles would be navigation as subtitles are obviously synced with time. So in reverse one could search by dialogue and find the spot from there. This was demoed a year or so back but was never put to use.
The anime extractor would be most useful for me though :p But yeah I love the developement in this department so, thank you.
> A side from subtitles it would be cool if Nepomuk could handle lyrics too.
DeleteLyrics are a nice addition.
I see if I could add this easily (seems musicbrainz does not offer lyrics)
> One of the big possibilities with subtitles would be navigation as subtitles are obviously synced with time. So in reverse one could search by dialogue and find the spot from there.
That is a great idea. But seems to be a lot of work, as I'm not sure the ontology to represent such a think exist for nepomuk. Maybe if we do have the groundwork done, someone find a good way to couple this and create this kind of functionality.
Hi,
ReplyDeletethe functionality and opportunities here are really great. I personally often store many papers for the topics I work on, and have some problems organising them. Directory trees just don't really fit. Some papers are mainly for the basics, some for the state of the art resp. related work, some topics touch, some topics overlap, I guess you know the problems. I often also store papers that I find personally interesting to read later and don't know where to put them. So, to summarize, I would be really happy to get this.
I'm just a bit concerned about the future of these features. I didn't come to a clear conclusion, yet, but perhaps my thoughts can be helpful as feedback anyway.
Many people complain about the resource strain that is libstreamanalyzer already. So although this metadata extraction from the web seems clearly logical, the GUI must be smart enough to be comfortable for users that want the feature and those that don't. The entry in the services menu seems like a good first choice, but in the long run, I think it would be a bit wasted, because the feature should actually make us more independent from the directory space. However, doing everything automatically would be too much of a resource hog. Conflicting requirements...
I'm also not so sure about the relation to libstreamanalyzer. It already scans the whole pdf, doesn't it? I mean, what does https://projects.kde.org/projects/kdesupport/strigi/libstreamanalyzer/repository/revisions/master/entry/lib/pdf/pdfparser.cpp do?
Perhaps the extraction from the web should be directly tied to this library, or the kded service that controls it? If there are more "collectors" in the future, it clearly needs scheduling and concurrency.
> Many people complain about the resource strain that is libstreamanalyzer already. So although this metadata extraction from the web seems clearly logical, the GUI must be smart enough to be comfortable for users that want the feature and those that don't.
DeleteI don't think this kind of metadata fetching should be combined with the libstreamanalyzers. Like you have said they already stress the system enough already.
I like to have this separated so that the user can:
* Fetch metadata for the current file from within a program. Fetch movie data while watching it with bangarang, fetch song data (lyrics and such) while listening to it, fetch additional information while looking at some pdf article and so on.
* Or the user explicitly wants to "mass-fetch" a lot of files. Which is also available via command line, dolphin extension or could be integrated into any program. For example in Conquirere, "fetch meta-data for the current project/selection)
* automatic background fetching only if the user enabled it on his own and really wants this. I don't think this should be a default option. Simply because it is not possible to have such a service without user interaction. Also it is kinda pointless to do large internet queries if no internet connection is available and really not desired if the user currently use mobile internet and has no flatrate and so on.
> The entry in the services menu seems like a good first choice, but in the long run, I think it would be a bit wasted, because the feature should actually make us more independent from the directory space.
We will never get rid of the "sort all files in folder structure". Nepomuk is designed to work differently, but most people will still sort their files as they are used to do. So such a dolphin extension will always make sense to me.
Still programs that use Nepomuk with its full potential don't need to bother with file/folder structure and call such a metadata extractor the way they need it. Sorting all this data is then up to the program.
> I'm also not so sure about the relation to libstreamanalyzer. It already scans the whole pdf, doesn't it?
The streamanalyzers retrieve as much information as possible from the local file and put it into the nepomuk database.
The reason I parse the RDF data on my own and also the first page for the pdf is because the streamanalyzer does not index most of my articles (that a bug in there).
When everything works as it should be the chain of execution will be:
* new file found/added to the harddrive
* libstreamanalyzer index it
* all relevant data is added to the nepomuk storage
* Now either:
** The user starts metadata extraction from the web on his own or
** the nepomuk resourcewatcher picks up that a new nfo::Document was added to the system and start the web extraction on its own
So usually I would reuse the information gathered by the streamanalyzer and don't try to get it on my own again.
> Perhaps the extraction from the web should be directly tied to this library, or the kded service that controls it?
Like I said above, The streamanalyzers should always be running because their are essential for nepomuk. The web-extraction should not, as not every user might want this and definitely not all the time running in the background.
> If there are more "collectors" in the future, it clearly needs scheduling and concurrency.
That's a reason why I'm not sure such a system should be enabled to work in the background all the time. This will result in many annoying windows asking the user what entry he wants to use and stress the system more than necessary for the all day work.
I guess I let this be a service than can e triggered whenever the user needs it or some other program wants to make use of it.
> That's a reason why I'm not sure such a system should be enabled to work in the background all the time. This will result in many annoying windows asking the user what entry he wants to use and stress the system more than necessary for the all day work.
DeleteWell, the way I see it, if the fetching is done in the background, no question is asked to the user. The questions should however be stored (and made accessible for other programs to show it to the user, so for instance when I run bangarang, it asks me about the last tv shows where the search failed/returned several results, or so I can have a plasmoid that shows me that, or ...).
Also, the background fetching should be enabled on a per-source basis.
And, now that nepomuk seems to the point were amazing things like that can be done, it would be great if this could be displayed more prominently to the user (I have no idea how. Maybe a nepomuk-based file manager?)
> -IMPORTANT! Have it let you manually enter search fields for results in the case that it doesnt automatically show the correct results
ReplyDeleteYou mean, if no result or just wrong results are returned. The user should also be able to enter the title (or other search parameters) on his own and search again?
> -Allow the user to change what metadata fields are fetched and plugged into nepomuk so that information the user isnt interested in doesnt get fetched.
I will add this and other options when I add a KCM around all of this
> -Besides that, just work on the interface some and it seems like a super useful feature that Im sure will get lots of attention if implemented correctly
The interface is just a "prototype" to get things done at the moment. Still I'm not quite sure how all of this features could be presented nicely to the user.
Currently it is horrible if someone wants to fetch the metadata for a lot of files. There will be a lot of "pop-up windows" everytime no exact search result is returned.
I'm not sure if I should hide more information or present them all.
Or if it would be better to start the search for all files and only ask the user for his selection at the end, so the fetching does not stop with every file
Also I'm not sure a full bloated window is a good choice or if a background daemon that interacts with the kde notification system might be better
It would be nice to extract file info from the filename or path. I'm using Mendeley with the "File organizer" option which rename the files according to patterns such as author-year-title-journal. This option will be a good gateway for people who have already a collection organized by folders or filenames for files with bad metadata.
ReplyDeleteBetter heuristics to determine good search parameters or actual information will be added later on too. There are a lot of options what could be scanned to get such info.
DeleteFor the moment I'll keep it simple even if this will result in somewhat worse results at the end.
But your concerns will be addressed.
If we are lucky there might be a propper writeback service one day (seems last years GSOC already had such a thing). So we could get proper results from the file, add more from the web and write all of it in a clean way as RDF back into the pdf.
Hei! Great new project! Do you have any idea about what happened to the old web-extractor?
ReplyDeletehttps://projects.kde.org/projects/playground/base/nepomuk-web-extractor
It seems this project is abandoned.
DeleteThat's why new ways to get a solution to the web-extractor thingies pop up more and more on the kde planet.
Hopefully my solution will end up as an easy to maintain replacement for the web-extractor. But I will focus mostly on the publication metadata fetching, as this is what I need for Conquirere
> Check out Calibre, EasyTag, and Kid3 for examples of metadata editors [...]
ReplyDeleteI will have a look at this. Thanks
> Calibre allows for the manual editing of metadata as well though, which Im not sure if you were interested in working on.
Might be nice to have such an option available, but this is not my first goal. Once simple fetching from the web works reliable and without to much annoyance to the user I will expand it as much as needed.
> I think Im going to make a few mockups of my ideas for you if I have some time today.
Some mockups would be a great help. Thanks for the offer
Hello Dude,
ReplyDeleteKDE is a free software project based around its flagship product, a desktop environment mainly for Unix-like systems. The term remote desktop refers to a software or an OS feature allowing graphical applications to be run remotely on a server, while being displayed locally. Thanks a lot.....
Extracting Data From Web Pages