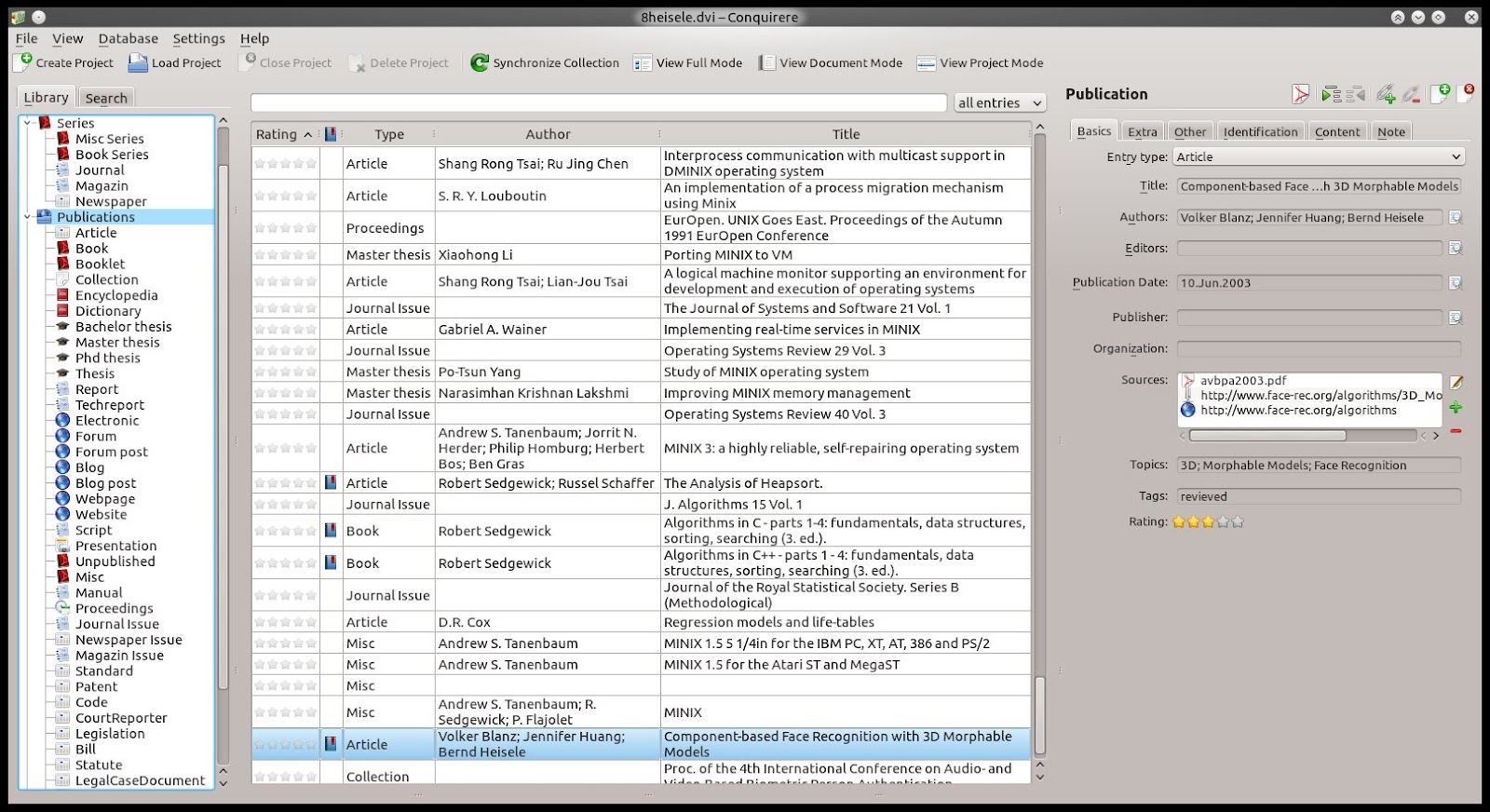
Tuukka told me he developed a python plugin based Konqueror system that extracts publication relevant metadata from the currently visited website. If you know Zotero, this should remind you of the translators they are already using.
Extracting metadata from the web is a nice addition to the whole Nepomuk idea. There already exist a few implementations to extract tvshows, websites, movies and there was once a GSoC fully related to this topic.
One of the comments below Sebastians tvshow extractor was about the extension to also fetch anime data. Of course this is just one idea, there are hundreds of other sources where such data can be retrieved from. Also why stop with video files, there also exist music, publications, books and other files where additional metadata from the web can be a real help.
Now we could start to write a new program for any website we want to fetch the data from, but at the end we will only have a lot of copy and past code with some minor changes in it.
As I wanted to add such a metadata extraction for my Conquirere program anyway I sat down and thought of a more general way to combine all of this.
The "Nepomuk-Metadata-Extractor" was born. Hopefully this time the name was better chosen than the last one.
So what is this all about?
I sat down with Tuukka and combined his great python work with most of what Sebastian created for his tvshow stuff.
The end result is now a small little program, that can be called from the command line with the url of the file or folder you want to scan. Also you can simple select the right action from within dolphin if you prefer.
At the moment the program will detect if you scan publications (.pdf or .odt) or if it is a movie/tvshow.
In case you have a movie, you can fetch all the necessary data from imdb, for the tvshow it will fail, as I haven't implement this part.


The publication scan will do some more neat things.


The publication scan will do some more neat things.
First It starts by retrieving as much information from the file as possible.
This is done by scanning the RDF part of it. As most of my pdf articles have lousy RDF metadata attached to them, I also try to extract the title from the first page of the pdf.
Now that we got as much information as possible the program starts a search via Microsoft Academic Search to get the relevant abstract, bibtex data and all references used by the publication and fills the nepomuk database with it.
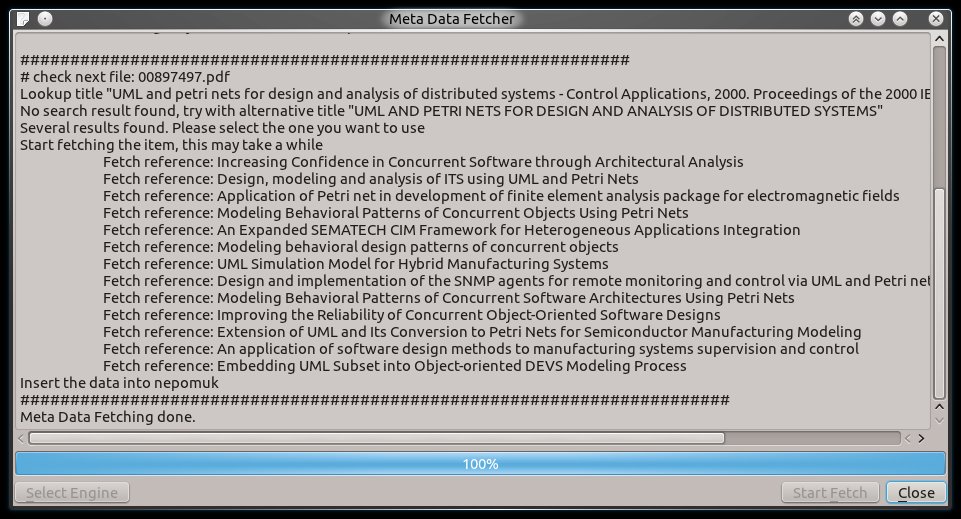

But what about the python part I've talked about earlier?
The actual search and extract job is done by a really simple to write python file. Currently I have written only two of them, but in the future you can extend it easily and then select the the right backend directly from the program.
So here we are with a new little program.
I will add this functionality into Conquirere later and hopefully Tuukka will release his Konqueror plugin later on too.
The question is just, should I add support for tvshows?
Is this the right way to start a more general web extraction service?
What do you think about this?
It could be extended with a KCM, so that someone can specify the default engine used for searching. Also a backup search engine, if the first one fails.
Sebastian also added a Nepomuk:Service so his fetcher is executed once the libstreamanalyzer adds a new video file into the storage, the same could be done here just for all kind of files.
Currently the whole system is created around files to scan, but it is also very easy to extend it, so any kind of nepomuk resource can be fed to the python parts to fetch all kind of data from the web.
If you want to try it out, the sources are currently located in my scratch repo and soon in the KDE playground.